Skip to content
Danish's Blog
Portfolio
Blog
Let’s talk 🚀
Category:
Tutorials
WordPress Heading Anchors: Automatically Create Link Targets
December 5, 2024
How to Cache POST Requests in Nginx
March 6, 2024
Protected Routes in Next.js
November 27, 2022
Getting Started with DatoCMS – Creating a simple blog
December 11, 2021
Grafana Loki – How to Monitor Server Logs Like a Pro!
November 27, 2021
Alfred – Slack Bot to Post Birthday and Anniversary Messages
October 25, 2021
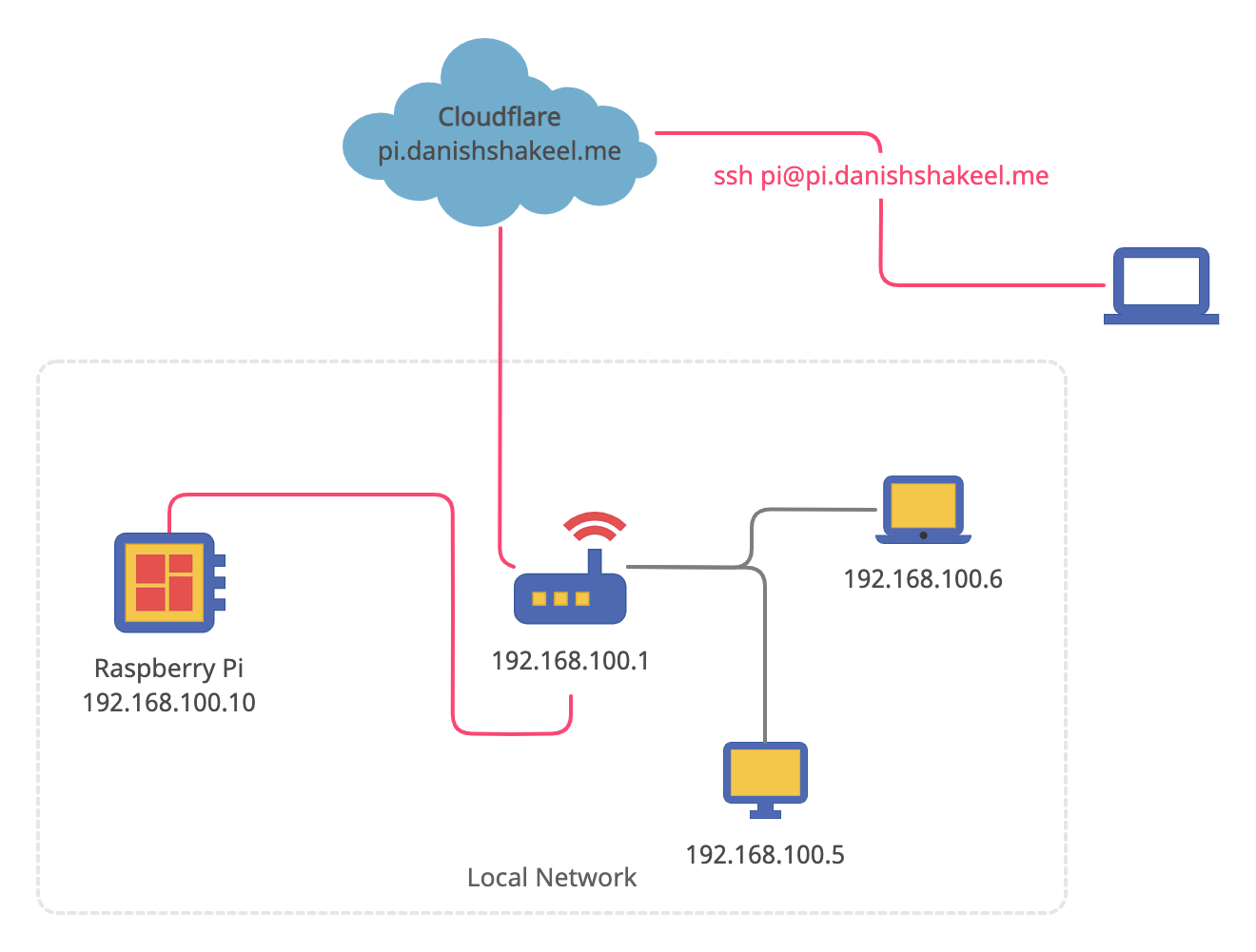
Creating an SSH Tunnel using Cloudflare Argo and Access
October 9, 2021
Wildcard SSL Certificate on Linode using Certbot
September 19, 2021
Configure Logitech MX Master 3 on Linux (LogiOps)
September 13, 2021