Skip to content
Danish's Blog
Portfolio
Blog
Let’s talk 🚀
Category:
Servers
The 18-Second Request: Tracing a Latency Bug to a Hidden Retry Loop
January 7, 2026
sshc: a simple command-line SSH manager
August 29, 2024
How to Cache POST Requests in Nginx
March 6, 2024
New Relic with WordPress using Event API for better monitoring
December 9, 2023
Grafana Loki – How to Monitor Server Logs Like a Pro!
November 27, 2021
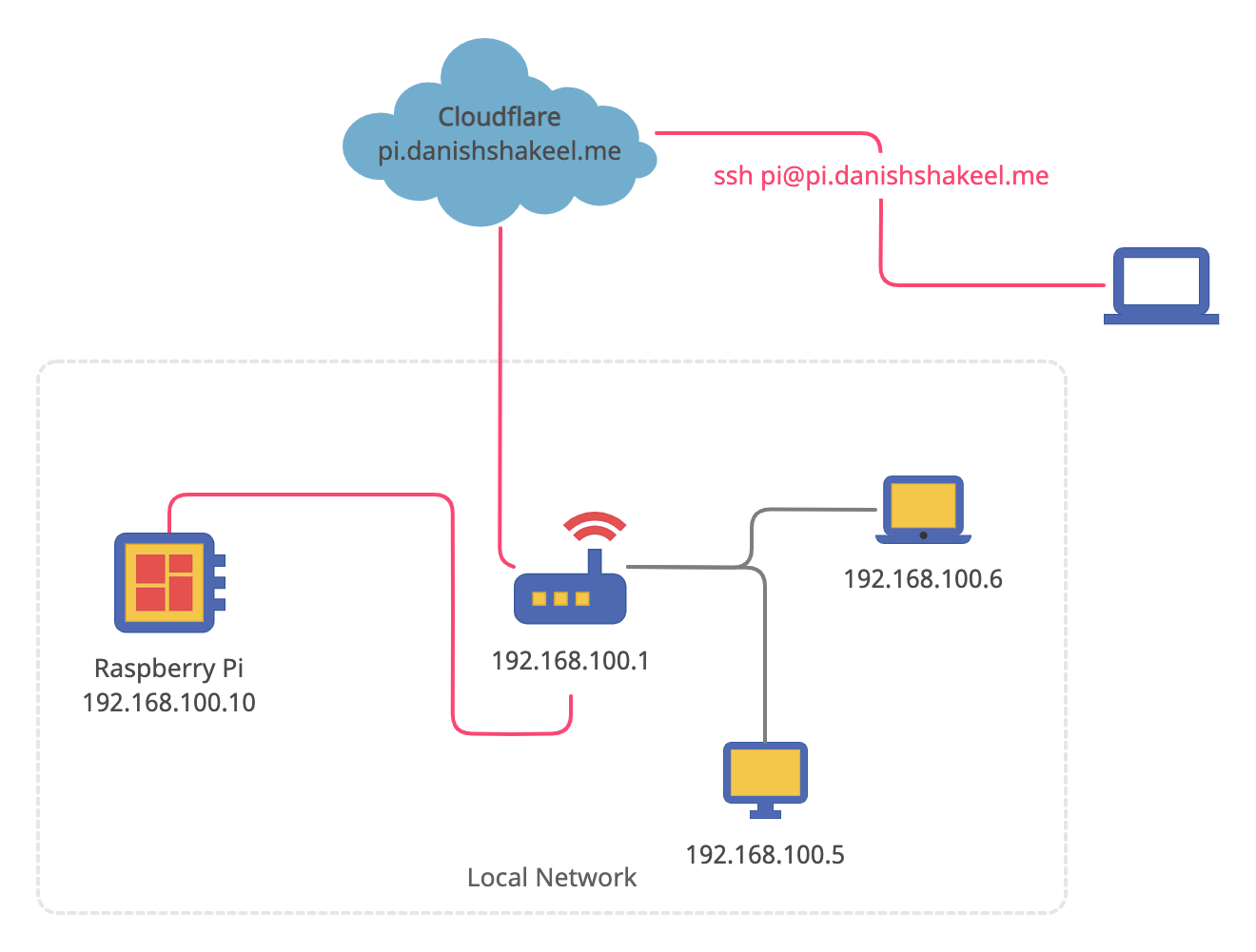
Creating an SSH Tunnel using Cloudflare Argo and Access
October 9, 2021
Wildcard SSL Certificate on Linode using Certbot
September 19, 2021